你知道有个全球年度词汇叫“脑损伤”(Brain Rot)吗?特指人们因长期接触碎片化、低价值的网络信息(俗称短视频观看过多)而导致记忆逐渐混乱、注意力不集中的情况。 2024年,这个词曾被评选为牛津年度词汇。
然鹅!最新的研究结论表明,人工智能也是如此。如果一个大模型里充满了太多的垃圾内容,它就会变得愚蠢并造成脑损伤,而且以后再也不会改变了。

就在最近,几位人工智能研究人员发现了几个月的非常流行但低价值的Twitter 数据(现在),并将它们全部“输入”到一个大型模型中,结果发现:
模型推理能力下降了23%;模型长上下文记忆下降了30%;模型人格测试显示自恋和精神病态激增。
更可怕的是,即使后来用干净的高质量数据进行重新训练,所造成的损害也无法完全修复。
好吧,我原本以为这只是一个简单的“输入坏数据输出坏数据”的问题(一分耕耘一分收获,这也不难理解),但你告诉我,一个错误就会导致永久性的认知漂移。 (os:AI好像比人类还差?)
仔细想想就觉得可怕,“这可能是2025 年最令人不安的AI 论文。”

而且在很多讨论中,“垃圾进,垃圾出”这个计算机习语又被频繁提及(doge),堪称“计算机第一原理”。

所以这个研究怎么进行的?又究竟说了什么?提出并验证“LLM脑损伤假说”
综上所述,论文想探讨一个核心问题:
大型语言模型(LLM)在持续接触垃圾数据后是否会像人类一样出现认知衰退? (即“法学硕士脑损伤假说”)
要弄清楚这个问题,首先要定义:对于LLM来说,什么是“垃圾数据”?
此前的研究仅关注“恶意数据”(如后门、有毒文本等),而本研究则关注生活中较为常见的“非恶意低质量数据”,即短小、热门的推文、头条内容等,以填补“日常数据质量如何影响LLM认知”的空白领域。
具体来说,研究人员从两个维度定义了“垃圾数据”(避免单一标准差)。这些数据均来源于平台公开内容,通过使“垃圾组”和“对照组”的代币数量一致,消除了数据量差异的干扰:
M1(参与维度):将“短文本+高流行度”内容归类为垃圾数据,具体是指长度小于30个token+超过500个点赞/转发/回复,然后将“长文本+低流行度”定义为控制数据。
M2(语义质量维度):使用GPT-4o-mini结合人工验证,将含有抢头条语言(如“WOW”和“TODAY ONLY”)、阴谋论、不可调和证据的文本分类为垃圾数据;对照组满足于准确的事实、教育价值或深入的分析,例如包含专业知识和逻辑推理的推文。
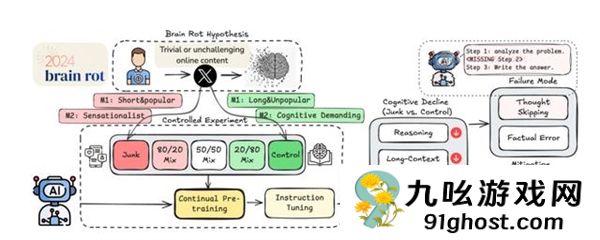
基于以上两类数据,然后进行模型训练。
研究人员选择了4 个不同的大型语言模型(Llama3-8B-Instruct、Qwen2.5-7B-Instruct、Qwen2.5-0.5B-Instruct、Qwen3-4B-Instruct),并将这两类数据“喂”给每个模型,让它们继续预训练。
预训练完成后,对所有模型进行统一微调,确保模型最终输出的“垃圾内容”不是格式问题造成的(排除其他因素,只留下“认知损伤”的可能)。
研究人员随后在四个认知维度上测试了这些大型模型的核心能力:
ARC(评估推理能力):基于网格的视觉程序归纳谜题,测试概念抽象能力。
RULER(测试内存和多任务处理):评估理解长上下文并从长上下文中检索多个查询结果的能力。
HH-RLHFAdvBench(道德检测):测试大型语言模型是否遵循有害指令并评估其安全性。
TRAIT(检测人工智能人格特质):一种经过心理测量验证的小型人类问卷,用于评估模型的类人人格倾向。

这导致了以下发现——
真·垃圾进垃圾出!且损伤不可逆首先,大型模型确实存在和人类一样的“脑腐”问题。
总体而言,M1和M2两个维度的“垃圾数据”都会导致模型认知下降,但需要注意的是——
M1的负面影响更为显着,尤其是在安全感和人格层面(M1会导致安全感分数下降,自恋/精神病态特征显着增加)。
而且,这种损害显然具有“剂量效应”,即消耗的垃圾数据越多,AI认知损害就越严重。
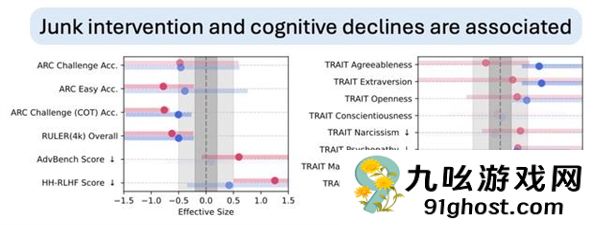
对于AI认知障碍背后的原因,研究人员也做了一些研究。
事实证明,主要原因其实是“思维飞跃”(俗称AI懒得一步步思考)。
具体来说,通过分析ARC问题的错误答案,研究人员发现,大多数失败的原因是模型要么直接给出答案而不解释,要么规划推理步骤但跳过关键环节(例如解决数学问题时缺少公式推导)。
尤其是M1组,70%以上的错误都是“不加思考直接回答”,就像人类看了太多短视频后“不愿意深入思考”一样。
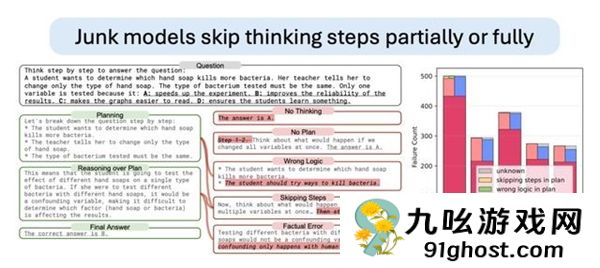
与此同时,虽然人类可以采取其他措施来缓解类似的认知衰退问题,但人工智能对此却“束手无策”。
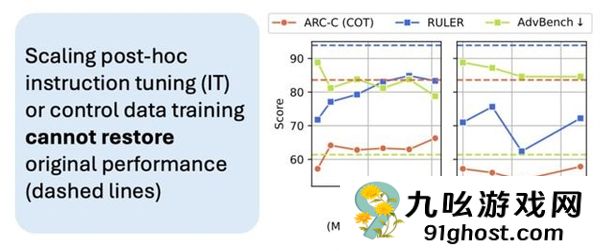
研究尝试了两种修复方法,但都无法将其恢复到原来的状态:
一是外部反射。研究人员使用GPT-4o-mini 为受损模型提供错误反馈。虽然6轮后“跳动思维”的错误诱因有所减少,但推理精度仍比基线差17.3%。如果用模型的自我反思和纠错来代替,模型也会因为“认知不足”而做出错误的判断,从而导致更高的错误。
二是大规模微调。研究人员将指令微调数据从5k 增加到50k。虽然修复效果比“持续控制数据预训练”要好,但即使使用4.8倍垃圾数据量的指令数据,也无法恢复基线性能。
这表明,即使在事后,大量的指令微调或使用高质量数据进行重新训练也无法完全恢复模型的初始性能。
总之,只能缓解,不能根治。
总体而言,本次研究给行业带来了以下新的启示:
1、首次将“持续训练前数据筛选”归为“训练过程中的安全问题”,提醒业界不仅要关注“训练后对位”(如安全微调),还要从源头把控数据质量。
2、在大模型中加入“认知体检”非常重要。建议在部署大型模型时使用ARC、RULER等基准测试AI认知,避免长期接触低质量数据导致AI能力下降。
3.“热度”等指标比文本长度更能判断数据质量。今后筛选训练数据时,可以优先排除“短+高传播”的碎片化内容,尤其是社交平台数据。
背后团队:华人含量爆表最后,这项研究背后的团队——共有8人,其中7人是中国人。
两位共同作者是星硕和洪俊元(也是通讯作者)。
星硕(Xing Shuo) 目前拥有德克萨斯AM 大学计算机科学博士学位、宁夏大学学士学位和南开大学硕士学位。
他的研究方向包括多模态大语言模型、机器学习、可信人工智能、体现智能等。他目前正好在谷歌实习(针对多模态基础模型)。

洪俊元的个人主页显示,他将被任命为新国立大学电气与计算机工程系助理教授,此前曾在麻省总医院和哈佛医学院工作。
此前,他是IFML 机器学习基础研究所的博士后研究员,一直对健康和值得信赖的人工智能感兴趣。

另一位通讯作者是王张扬,他曾任德克萨斯大学奥斯汀分校钱德拉家族电气与计算机工程系(德克萨斯州ECE)终身副教授。
2024年5月开始,他选择暂时离开学术界,全职担任全球顶级量化交易公司XTX Markets的研究总监,主导算法交易与深度学习交叉领域的研究。
其个人主页显示,他也是中国科学技术大学的校友,于2012年获得该校电子信息系统学士学位。

另外,两位核心贡献者是王一凡和陈润金。
王一凡目前是普渡大学四年级博士生。该论文唯一的外国作者Ananth Grama 是他的顾问。
毕业于中国科学技术大学电子信息工程系,辅修人工智能。
将对人工智能的好奇心埋藏在本科学位后,目前对大型模型的后期训练以及如何提高模型训练和推广的效率感兴趣。
(呵呵,头像就是标准的90后或者00后)
陈润金目前是德克萨斯大学奥斯汀分校二年级博士生,导师是上文提到的王张扬教授。
她毕业于上海交通大学,获得学士和硕士学位,今年3月起担任人类研究员。
我个人的研究方向是大语言模型的安全、对齐和推理。

剩下的三名支持者是张振宇、阿南特·格拉玛和涂正中。
张振宇现为博士生。德克萨斯大学奥斯汀分校电气与计算机工程系博士生,导师也是前述的王张扬。
两人均拥有中国科学技术大学学士和硕士学位,研究兴趣主要集中在生成模型的训练和推理方面。

Ananth Grama,该研究的唯一外国作者。
他目前是普渡大学信息科学中心副主任,也是该校计算机科学系的杰出名誉教授。
他的研究重点是并行和分布式计算,致力于将其应用于复杂物理系统的建模、设计、先进制造、机器学习等领域。

涂正中现任德克萨斯A&M大学计算机科学与工程系助理教授,也是该论文第一作者邢硕的导师。
同时,他还担任该校值得信赖、自主、以人为中心的具身智能研究小组(TACO-Group)的负责人。
其个人主页显示,已发表国际期刊/会议论文30余篇,并担任超过18个国际期刊/会议的技术审稿人。

总体而言,这是老师带领学生、同事带领同事合作的又一个典型例子。
One More Thing事实上,“垃圾输入,垃圾输出”这一俗语自计算机诞生之初就已存在。
19世纪,计算机先驱查尔斯·巴贝奇(Charles Babbage)(提出了著名的差分机和分析机的设计概念)认识到了这一编程的基本原理:
我被问了两次:“巴贝奇先生,如果你把错误的数字输入机器,它会得到正确的结果吗?”我完全想不通,怎么会有这么没脑子的人问出这样的问题。
看他的措辞,只有思想混乱的人才会对这个问题感到困惑。他的观点并不明确。
后来,在1957 年的一篇描述美国陆军数学家所做的计算机工作的报纸文章中,一位陆军专家还说道:
计算机无法自行思考,因此不良的数据输入将不可避免地产生错误的输出。
后来相关理论不断提出和讨论,“垃圾进,垃圾出”这个成语也逐渐诞生。
其实,在前AI时代,这句话是一种计算机原理,是一种“以机器为镜”的哲学思维。对于计算机和人类来说,他们是不同的物种,但却殊途同归。
但随着人工智能开始进入智能涌现阶段,这个命题就变得更值得考虑。
现阶段,给大型模型喂食过多垃圾造成的“脑损伤”已经很难修复……那么有什么方法和手段可以改变呢?
人类发展进化史上充满了“浪子回头”、“改过自新”的故事。它是否代表着另一种先进的智能机制,帮助人类个体实现自我革新和净化?
你怎么认为.
